

Plan-based TORQUE scheduler
Introduction
This pages summarizes our recent research and implementation of a plan-based TORQUE scheduler.
Plan-based TORQUE scheduler represents a unique solution - it is an implementation of plan-based job scheduling system within the mainstream TORQUE resource manager.
Thanks to the plan, this scheduler can plan ahead job execution, thus improving predictability. Moreover, prepared plan is evaluated and optimized with respect to several important optimization criteria.
Design
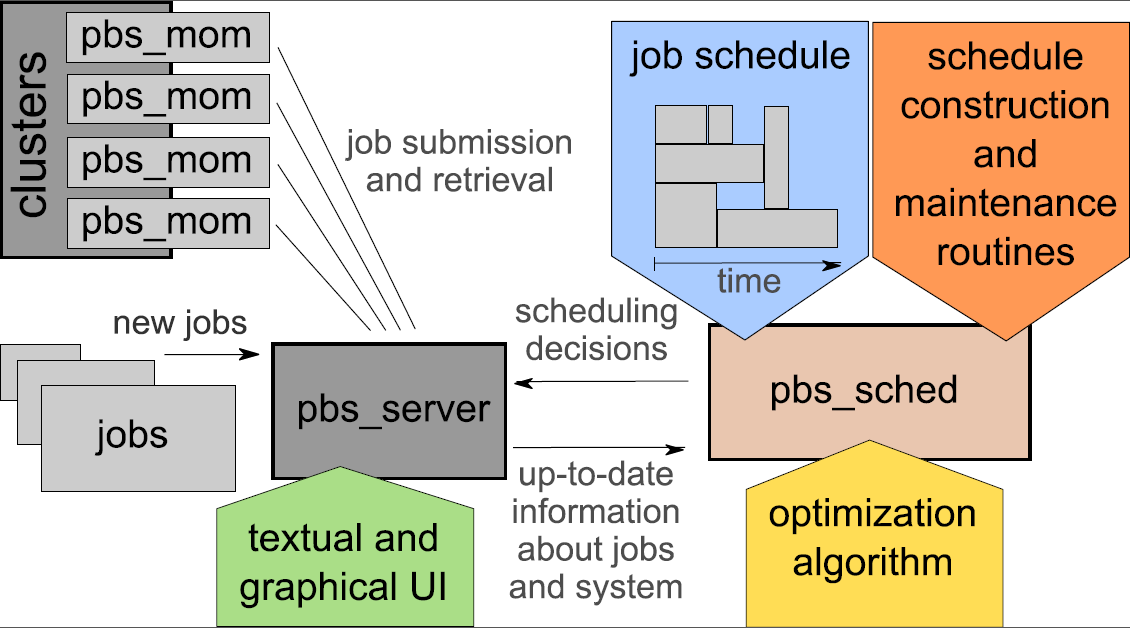
The newly developed scheduler is implemented in the pbs_sched module of the classical TORQUE resource manager.
Instead of queues, it uses a schedule data structure (plan of execution) to store jobs prior their execution. using the schedule, estimated start time, completion time as well as machine(s) are known in advance.
Moreover, schedule is evaluated subject to various optimization criteria and optimized using a metaheuristic, which is a local search-based optimization algorithm.
Data Structures
The schedule is represented by a linked list-like data structures. Two independent lists are used - the first one stores jobs while the second one store "gaps" that appear in the schedule.
Scheduler Management Routine
The scheduler's behavior is managed by SchedulingCycle method. Using it, the job schedule is built, maintained and used according to the dynamically arriving events from the pbs_server. It is executed every time a new information concerning the state of the system is received from the pbs_server. Typically, this happens as a result of new job arrivals or (early) job completions. Also, schedule optimization algorithm is periodically invoked here, in order to increase the quality of generated schedule.
Scheduling Algorithms
The scheduler uses two main classes of algorithms. Schedule creation is done bz a backfill/like policy. When suitable, such a initial schedule is optimized by optimization algorithm.
Schedule Creation Routine
Initial schedule is created by a backfill-like policy which works similarly to Conservative backfilling.
Schedule Optimization Routine
Initial schedule is optimized by a local-search inspired algorithm called Random Search. Currently, it optimizes three criteria - bounded slowdown, wait time and response time.
User Interfaces
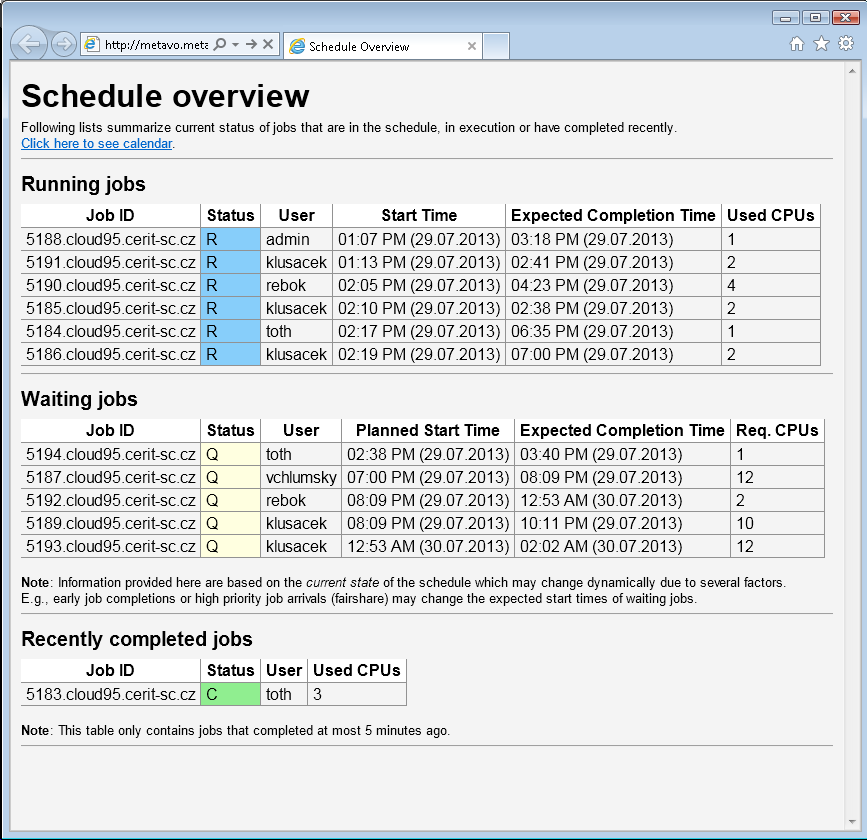
Information about current schedule are available either through standard qstat command or through newly developed web application as shown on the screenshot.
It displays relevant information about running, waiting and recently completed jobs. Especially, information about planned start/completion time is available via this interface
Developers
The leading designer is dr. Dalibor Klusáček who is the author of the crucial "know-how" which includes scheduling algorithms, optimization routines, data structures and related methodology concerning efficient application of schedule-based solution within a job scheduling system.
The main developer and the co-designer is Mr. Václav Chlumský who is the author of the code and is responsible for implementation of newly proposed features.
The main consultant of this project is asoc. prof. Hana Rudová.
Deployment
Presented job scheduler has been used in production service in CERIT-SC (http://www.cerit-sc.cz/) since July 2014. So far, it performs as expected, significantly increasing both the throuhput and the utilization within CERIT-SC system.
Download
Current stable version can be obtained at: https://github.com/CESNET/TorquePlanSched
References
- KLUSÁČEK, Dalibor, Václav CHLUMSKÝ a Hana RUDOVÁ. Planning and optimization in TORQUE resource manager. In Proceedings of the 24th ACM International Symposium on High Performance Distributed Computing. New York, NY, USA: ACM, 2015.
- Václav Chlumský, Dalibor Klusáček and Miroslav Ruda, The extension of TORQUE scheduler allowing the use of planning and optimization in Grids. Computer Science, 13 (2). pp. 5-19. ISSN 1508-2806, 2012.
- Václav Chlumský, Dalibor Klusáček and Miroslav Ruda. Planning, Predictability and Optimization within the TORQUE Scheduler. In Antonín Kučera, Thomas Henzinger, Jaroslav Nešetřil, Tomáš Vojnar, David Antoš. MEMICS 2012. první. Brno: Novpress s.r.o., 2012.
Experimental Evaluation Testbed and Setup
As this software is an actual scheduler instead of a simulator we cannot use the whole workload "as is" since typical workloads lasted for several months. Clearly, it would take too much time to evaluate the scheduler using the whole log. Instead of that we have extracted several "interesting" job intervals from each workload. First, we have plotted when there was a significant activity and contention in the original log, using the number of waiting jobs at the given time as a metric. Using this information we have extracted those intervals that lasted for at least 5 days and contained some reasonable number of waiting jobs. Such an interval was considered as promising, as it was more likely to show differences between different scheduling solutions. Finally we have divided job runtimes and all inter-arrival times between two consecutive jobs by a given factor. As a result we have obtained workloads which are proportional to the original ones and exhibit similar behavior, but have shorter durations (makespan), i.e., they are much more suitable for our experiments. For example, if the original data covered one week and we have used 7.0 as the factor, then it took only 1 day to perform the simulation.
So far, all experiments have been performed on an Intel i5 3.1 GHz machine with 8 GB of RAM. The machine hosted both the pbs_sched (scheduler) and the pbs_server. Execution nodes have been implemented using the Linux Container (LXC) toolkit. Using LXC, each node has been represented as a lightweight virtual machine with a pbs_mom instance. Job execution on such a node was processed as a simple sleep command, where the sleep duration was equal to the job runtime as specified in the workload.